Weighted Cell Information Gain¶
The CIG assumes that the unknown feature is independent from all other features. Features containing personal information often have inter-dependencies, e.g. firstnames and gender, or postcode and income.
One can look at the CIG as the worst-case scenario. Nothing of the uncertainty of the unknown feature can be explained by the other features.
The Weighted Cell Information Gain explores the best-case scenario: we assume that all observed correlations are due to causal dependencies between the features.
Let 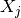 be the unknown feature. Then
be the unknown feature. Then 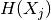 , the entropy of feature
, the entropy of feature 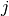 , describes the amount of
information contained in that feature.
The conditional entropy
, describes the amount of
information contained in that feature.
The conditional entropy 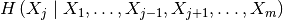 describes the
amount of information contained in feature , given that all other feature values are known (taking all possible
correlations into account).
describes the
amount of information contained in feature , given that all other feature values are known (taking all possible
correlations into account).
Dividing the conditional entropy by the entropy of the feature, we get a factor that describes what fraction of the information in a feature can not be explained by the correlations with all other features.
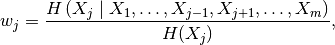
The wCIG is defined as the CIG value multiplied by factor 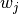 .
.
Caution¶
Correlation does not mean causation. A trivial counterexample is the following dataset:
A |
B |
|---|---|
a |
b |
c |
r |
f |
e |
There is a perfect correlation between feature A and B, thus all wCIG values are zero. However, there is no causal relationship between the two. In fact, the CIG values are quite high, as all values are unique.